For over eleven years, BigScoots has completely owned and operated all of our own server and networking infrastructure. Doing so has enabled us to create a managed hosting service that has always provided considerably more server and networking resources to our clients’ websites, been price conscious, and with significant network and server optimizations not possible otherwise – it is a big part of how we’ve become an industry leader in managed hosting.
In that eleven year period, our network has seen many different forms, always evolving to meet the needs of our growing client base. In the very early days we weren’t much more than a few servers and a business class switch, but today with many tens of billions of monthly requests our clients count on us to deliver for them, network capacity, performance and redundant demands are dramatically different than they once were. Our many phases of our most recent network upgrade has been ongoing for ~24 months, and is days away from completion – easily capable of delivering on the standards our clients expect of us, for years of growth to come.
I’ll be discussing our network as it was, is, and what it will be, digging into details along the way while also staying general when I can. If you have any questions, concerns, want to join in on the discussion or just reach out, please do! 👋
Our Network as of ~24 Months Ago
The most recent version of our network was completed roughly two years ago. At the time our most significant concerns were security and scalability.
Security is a bit of a default answer, it is always (or should be at least) at the top of any new network design. One of the big upgrades security wise for this version of our network was an upgraded series of hardware firewalls. It enabled us to put all of our management devices behind a redundant pair of firewalls – very critically this did not impact or slow down client site’s in any way, while providing a significant upgrade in server-side security to our clients.
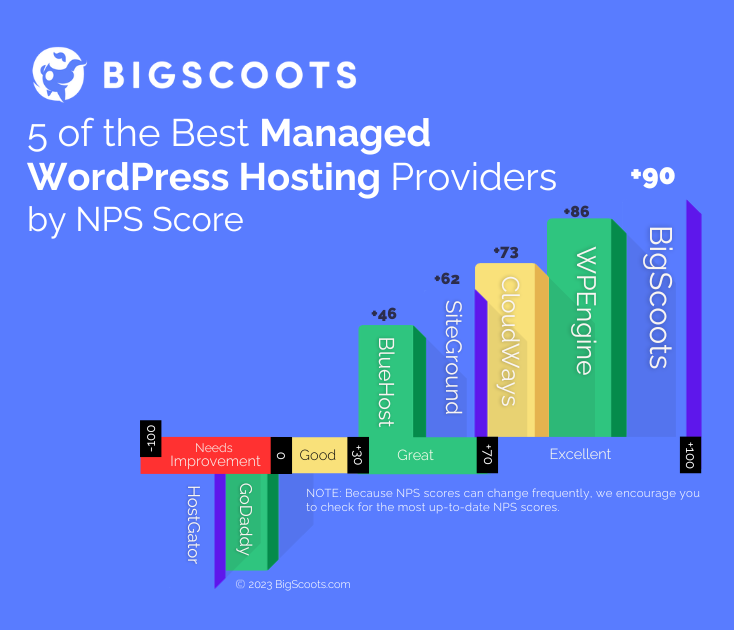
Scalability was a larger problem, and perhaps not in the way you might initially think. Network devices just like any piece of technology are built with various features and limitations. As we grew one of those limitations became quite apparent: The ports on our network devices were going to start limiting us if we wanted to continue operating as optimized as we have been. This meant that our connection speeds and capacity, as well as redundancies, could be impacted as we grew. It also meant that adding more servers and more racks those servers go into in the future would be impossible.
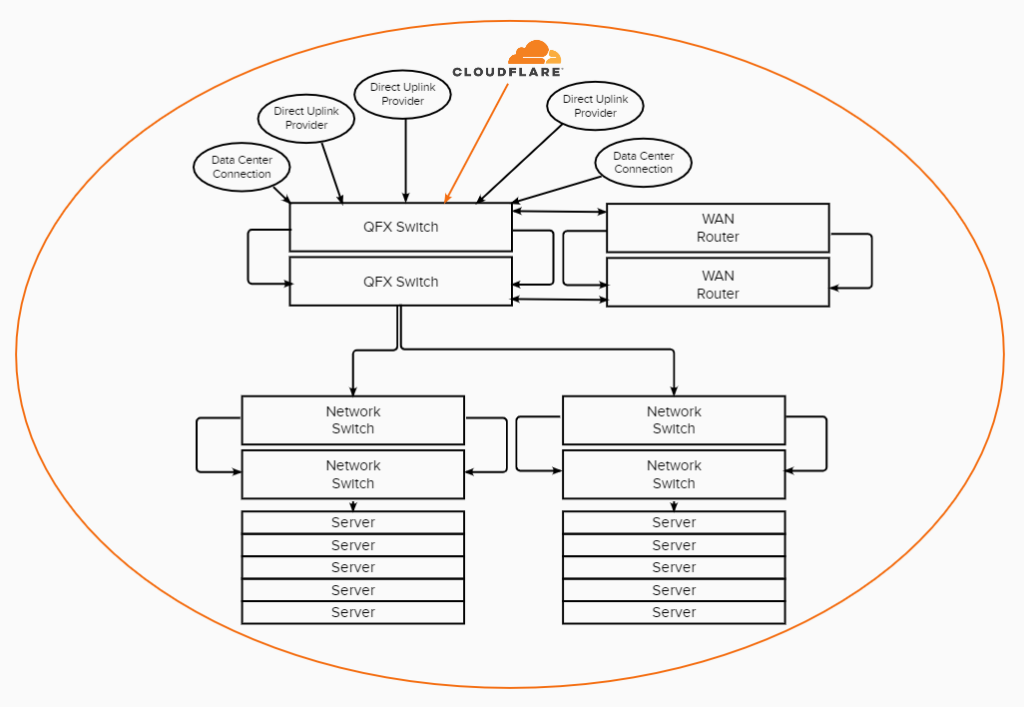
Our solution was a 3-tiered network. This removed the port limitation in our core network by creating a distribution layer, allowing us to both increase the bandwidth between current racks as well as connect new racks of servers without consuming highly valuable networking ports in our core infrastructure.
Problems with the Upgrade
Design and implementation of a network upgrade is all-consuming. It requires significant time and effort by many specialists, and in our case with the impossibility of any maintenance window (i.e. scheduled downtime) to implement a network change, the time and effort increases significantly to ensure no interruption is felt by our clients.
In this case, by the time our last iteration of our network was completed, enough time had past that we were already wanting to aim higher, with a few key problems in mind:
- Removing the reliance on a single network carrier and becoming multihomed, having multiple connections to the internet. This requires significant networking overhead, one that initially we relied on the data center to provide, but we knew we needed to take on ourselves. Although the data center themselves provide an uplink that has several carriers blended into it, if the data center had an issue, we had an issue. This would allow us to limit outages resulting from uplink provider issues as well as improve overall network performance.
- Security threats continued to grow globally, with more and more botnets and security concerns popping up daily, we wanted additional security than even just implemented.
- Adding in even more network bandwidth. Both our public (traffic to your website) and internal (your backups) traffic demands were growing considerably and we needed to stay ahead of demand.
- Increased redundancies throughout our network. Although every network device was already deployed with a failover, we wanted to increase that by adding more connections and more redundant devices where possible, to limit the potential of an issue actually impacting network performance or reliability.
New Network Design and Implementation
If we’ve learned anything by shooting to be the best managed host, it’s that you have to be open to changing proactively and doing better any chance you get – and it’s certainly no different when it comes to network upgrades. Growth, scale, security, customer concerns and needs are always changing, and even if you did it perfectly the last go-around, its a certainty that you’ll need to continue to do better to stay ahead of demand.
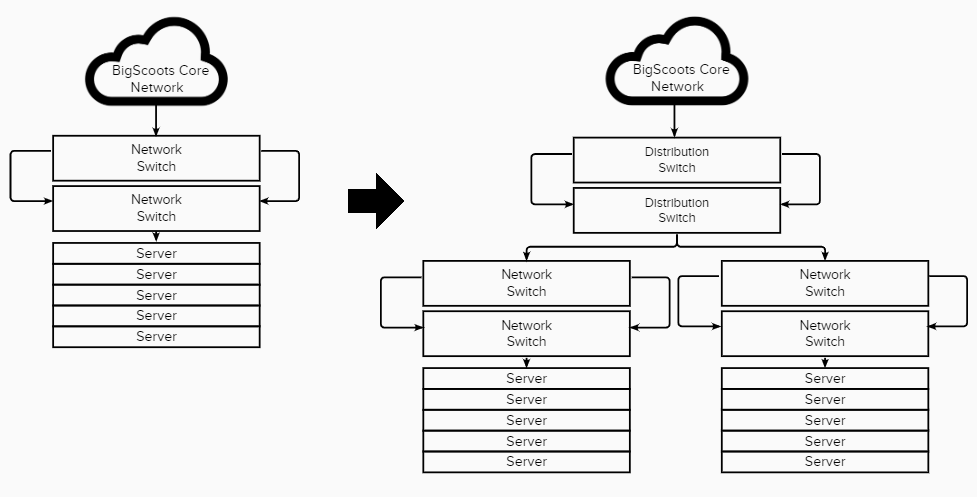
Step 1: Complete Control
One of the primary goals of this upgrade was to gain full and complete control over our network. Up until this point as most hosts do, we relied on two redundant connections by our data center, which they provided to us as a blending of multiple network carriers. However, if the data center themselves experienced an issue or perhaps one of their clients did, which is very common in the hosting world, that would impact us directly. So by us incorporating direct uplinks to tier-1 providers which we are directly connected to, the data center could completely fail without our clients being impacted for anything more than a few seconds.
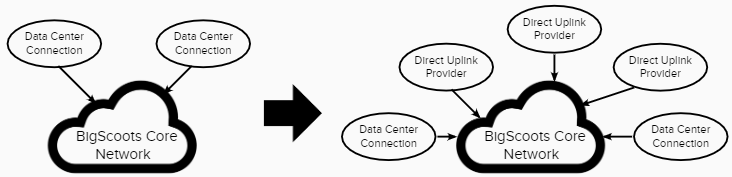
Step 2: Additional Security
Security comes in many different forms: You have to consider size, complexity and avenue of attack. When it comes to site and server security, we go to great lengths with our proactive monitoring and server-side firewalls. However network security can be significantly more complex because there are many billions of requests we need to get to the right destination, and any one of them could be malicious. We need to carefully filter all network traffic if we intend on effectively detecting and preventing network intrusions – enter Cloudflare’s Magic Transit.
Cloudflare has become a household name over the years and rightfully so. They have provided significant advancements in network security and optimization, and through our Enterprise Partnership with them, we’ve been able to leverage their security expertise. Specifically, because we own and operate our own network, we’ve been able to introduce Cloudflare “above” our network – filtering all incoming traffic for unlimited DDoS protection and various other security threats before they even touch our network. The beauty of this relationship is that there is no negative performance impact to our client’s sites adding in this protection, which is actually the opposite in other DDoS security relationships – this also secures all our network and management devices which in most hosting scenarios goes unprotected.
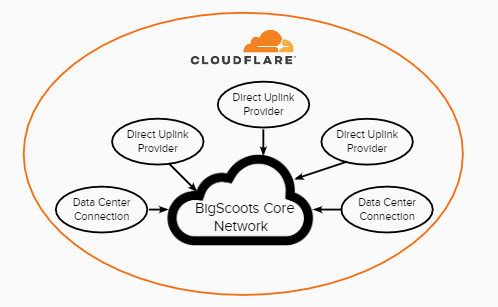
Problems with Magic Transit
Unfortunately we don’t yet live in an era where any technology is perfect, and Cloudflare’s Magic Transit is no different. Magic Transit does an incredible job at what it does and is trusted by some of the largest organizations on the planet, but ultimately filtering all incoming traffic does create a point of failure that cannot be avoided – if we went without this form of security, all sites would be exposed to the imminent threat of DDoS which is a far greater threat and is often the cause of the many hour+ long outages seen with hosting providers, rather than the rare issues we’ve seen with Magic Transit.
There have been scenarios that we’ve seen since this service has been implemented on our network where Magic Transit has failed in such a way that certain geographical locations were affected and others were not, and also impacted in some scenarios all incoming traffic for a brief period.
Going back again to owning an operating our own network, we have the flexibility to reroute our own traffic – so in the case of the the largest Magic Transit incident over the past 18 months where Magic Transit themselves were down for ~3 hours, we were able to route around them limiting the actual BigScoots impact to ~20 minutes.
We continue to evaluate Magic Transit on a regular basis as our DDoS provider of choice, but at this time are the clear industry leader.
Step 3: Network Optimization

While Cloudflare’s Magic Transit on its own is an industry leading security service, one additional benefit to our clients which is made available through our Cloudflare Enterprise Partnership and also by owning and operating our own network, is that we’re actually directly and physically connected to Cloudflare’s infrastructure. The Cloudflare Network Interconnect (CNI) is made possible as we share the same physical data center as Cloudflare.
This makes round trip traffic between our servers, Cloudflare and your visitors, as optimized as could possibly exist. In combination with the five tier-1 network uplinks, our network is globally diverse and incredibly optimized.
Step 4: Physical Location
Physical location is a huge part of hosting. Having a reliable, secure and redundant physical location to house your network and server infrastructure is paramount. Throughout this entire ~24 month period we have been going through the exhausting process of physically migrating to one of the most significant data centers in existence.
Our move to 350 E Cermak in Chicago, IL:
- Provided us access to true A + B redundant power. This means that our primary devices each have two physical power supplies, each going to a separate power distribution unit, each then going to its own circuit breaker, which then takes their own paths to the power distribution point in the data center, followed up by taking geographically diverse paths back to separate power stations. Having true A + B power means that power failure to our devices are incredibly unlikely.
- Made tier-1 networks directly accessible. We gained the ability to connect directly into all of our network uplinks, removing the reliance on a single uplink. This also created a significantly more optimized network in that we are able to route traffic through hundreds of thousands of different routes, getting your visitors to your hosting environment as optimally as possible.
- The physical connections directly into Cloudflare’s network possible.
- Puts us in the same footprint as some of the largest telecommunication companies and government organizations, dramatically increasing our physical on-premises security.
Step 5: The Final Stage

The final step of our ~24 month long upgrade is just days away and marks the transition onto significantly larger network infrastructure, setting us up for many years of growth ahead.
Network device resources due to our growth and increasing client needs started limiting the effectiveness of some of the networking protocols we rely on, causing situations where uniquely high resource-usage events could possibly result in a failure. The issue we saw a few days ago was an example of one such failure; a device did not failover appropriately after a firmware issue. Having more network resources available to facilitate the failover process would have completely circumvented the issue.
While it would have been preferable to increase network resources at the outset of the upgrade, or even more recently when network resource issues were starting to be detectable, this stage needed to be left to the end as all previous steps were required to set us up for a successful transition to our new, high-performance, high-density data center grade switches.
Redundantly connected, these new network devices are capable of many Bpps and Tbps of throughput, 40GBps individual connections quadrupling internal bandwidth, vastly superior monitoring, security, port capacity and reliability. Our network is changing form once again in this final stage to incorporate these new devices in a far more reliable, resource rich and performance oriented configuration.
On a personal note…
Our ongoing network upgrade is a testament to our never ending effort of improving, evolving and doing better every chance we can. This upgrade started in design years ago, and looked further and further ahead as our client’s demands grew. Having access to orders of magnitude more networking resources than we actually need, even during the highest of peaks, means we can grow along side our clients for years to come without any concern towards reliability and network performance.
There have been some headaches over these past two years that resulted from network growing pains and not being able to get to this final stage fast enough. Now that we’re here, our entire team is incredibly excited about being to able look forward into 2022, zeroing in and focusing on offering the best managed hosting out there. 🚀
We’re all so incredibly appreciative of having you here with us. BigScoots was started by Justin and me eleven years ago, simply wanting to offer the type of customer service that actually cared and the expert management we wanted for ourselves. Today, beyond our wildest dreams, we’ve been welcomed as an integral part of so many amazing clients’ businesses, sites, and communities and we couldn’t possibly be more grateful. Thank you for all of your support throughout the years; you can be absolutely certain we’ll continue to work as hard as we possibly can to deliver on our original promises and guarantees.
Scott – BigScoots CEO
With the final stage of the network upgrade slated to complete over the next ~7 days, this article will be updated accordingly.
Maintenance:
1-3AM CST Monday 27th
1-3AM CST Tuesday 28th
No impact expected, but ~5 minutes at most while DDoS protection gets reintroduced.

Written by Scott
BigScoots CEO and Co-founder